20강. 행 개수 구하기 - COUNT
대표적인 집계함수
COUNT(집합)
SUM(집합)
AVG(집합)
MIN(집합)
MAX(집합)
1. COUNT로 행 개수 구하기
집계함수(집합함수)는 인수로 집합을 지정함, 집합을 특정 방법으로 계산하여 그 결과를 반환
COUNT 함수 : 인수로 주어진 집합의 '개수'를 구해 반환
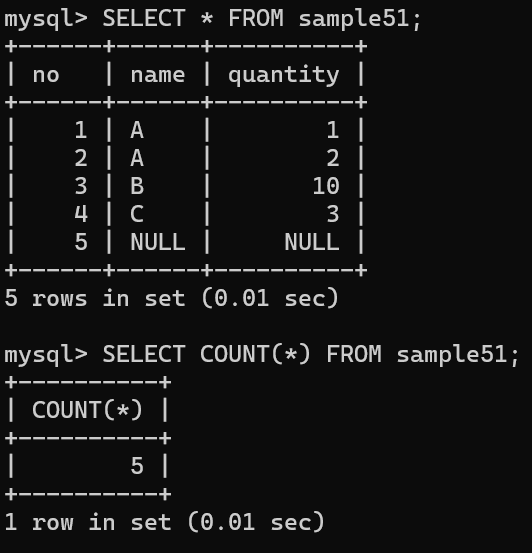
COUNT 함수를 사용하여 sample51 테이블의 행 개수를 구함
인수로 지정되어 있는 * 는 SELECT 구에서 '모든 열'을 나타낼 때 사용하는 메타문자와 같음
COUNT 집계함수에서는 '모든 열 = 테이블 전체'라는 의미로 사용됨
COUNT는 인수로 지정된 집합의 개수를 계산
집계함수의 특징
복수의 값(집합)에서 하나의 값을 계산해냄
일반적인 함수는 하나의 행에 대하여 하나의 값을 반환하지만, 집계함수는 집합으로부터 하나의 값을 반환
'집계' : 집합으로부터 하나의 값을 계산하는 것
- WHERE 구 지정하기

SELECT 구는 WHERE 구보다 나중에 내부적으로 처리됨
WHERE 구로 조건을 지정하면 테이블 전체가 아닌, 검색된 행이 COUNT로 넘겨짐
① WHERE로 행 검색 → ② COUNT로 행의 개수를 집계
2. 집계함수와 NULL값
COUNT의 인수로 열명을 지정할 수 있음
열명을 지정하면 그 열에 한해 행의 개수를 구함
*를 인수로 사용할 수 있는 것은 COUNT 함수 뿐 (다른 집계함수에서는 열명이나 식을 인수로 지정)
집계함수는 집합 안에 NULL 값이 있을 경우 이를 제외하고 처리
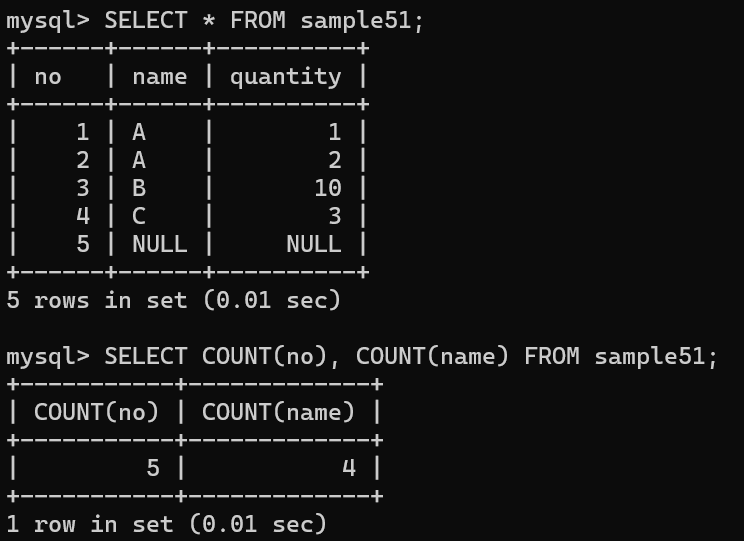
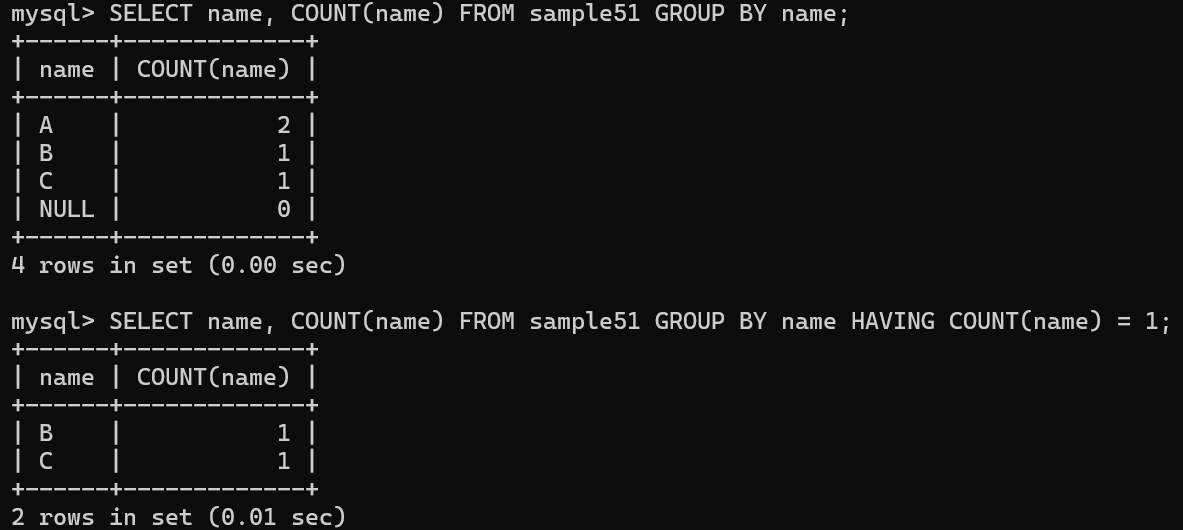
no 열의 행 개수는 5, name 열의 행 개수는 4로 나타남
→ name 열에는 NULL 값을 가지는 행이 하나 존재하므로 이를 제외한 개수 4가 됨
다만, COUNT(*)의 경우 모든 열의 행 수를 카운트하기때문에 NULL 값이 있어도 해당 정보가 무시되지 않고 5가 됨
3. DISTINCT로 중복 제거
집합 안에 중복된 값이 있는지 여부가 문제될 때도 있음
sample 51의 no 열은 1, 2, 3...과 같이 일련의 숫자로 되어 있어 중복X, name 열의 값은 맨 위 두 줄이 A로 중복됨
DISTINCT : 중복된 값을 제거하는 함수 를 사용할 수 있음
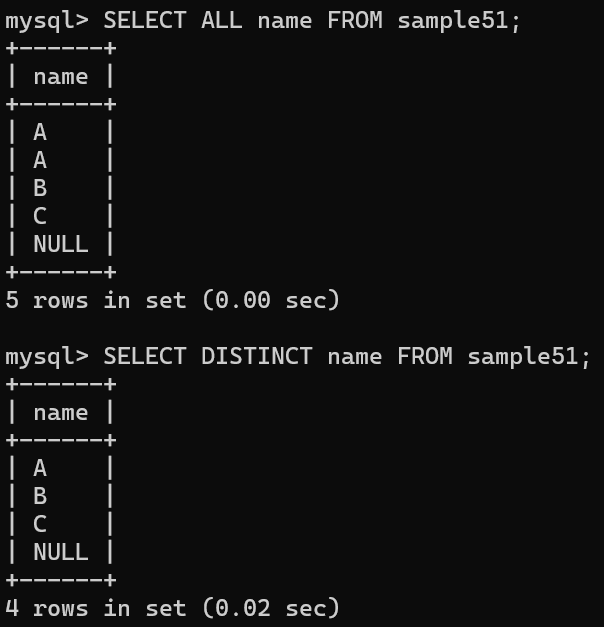
DISTINCT는 예약어
ALL 은 중복 유무와 관계없이 문자 그대로 모든 행을 반환
ALL과 DISTINCT 둘 다 사용하지 않고 생략할 경우, ALL로 간주
4. 집계함수에서 DISTINCT
NULL 값을 제외하고, 중복하지 않는 데이터의 개수를 구하려고 함
→ 집계함수의 인수로 DISTINCT를 사용할 수 있음

21강. COUNT 이외의 집계함수
1. SUM으로 합계 구하기
SUM 집계함수를 사용해 집합의 합계를 구할 수 있음

SUM 집계함수에 지정되는 집합은 수치형 뿐
문자열형이나 날짜시간형의 집합에서 합계 구할 수 없음
SUM 집계함수도 NULL 값을 무시 (NULL값을 제거한 뒤 합계를 구함)
2. AVG로 평균내기
합한 값을 개수로 나누어 평균값을 구할 수 있음
AVG = SUM / COUNT
AVG 집계함수에 지정되는 집합은 수치형만 가능
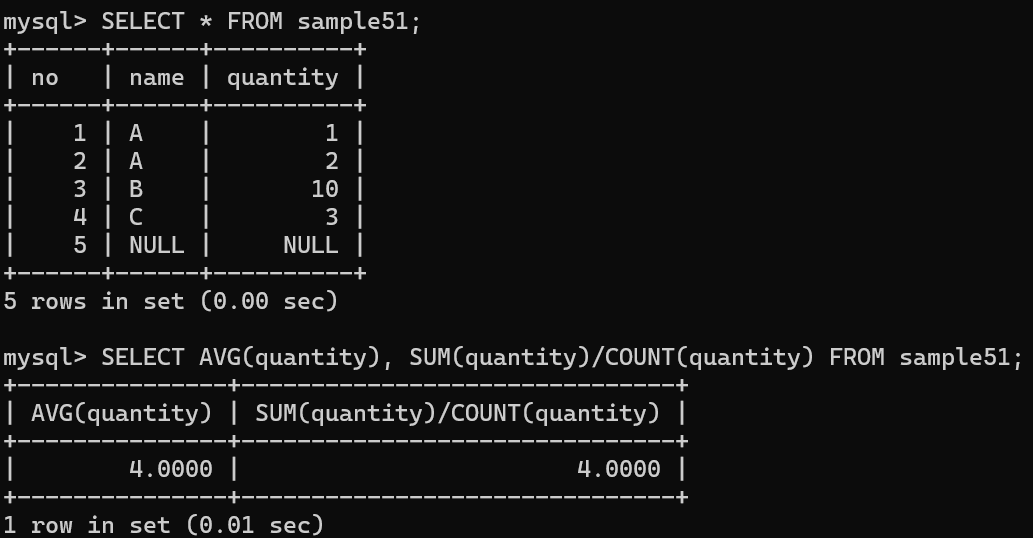
AVG 함수도 NULL 값 무시
NULL 값을 0으로 간주해서 평균을 내고 싶은 경우에는 CASE를 사용하여 NULL 값을 0으로 변환한 뒤 AVG 함수로 계산
3. MIN • MAX로 최소값 • 최댓값 구하기
MIN 집계함수, MAX 집계함수 를 사용하여 집합에서 최솟값과 최댓값을 구할 수 있음
이 함수들은 문자열형과 날짜열형에도 사용 가능
NULL 값은 무시

22강. 그룹화 - GROUP BY
1. GROUP BY로 그룹화
GROUP BY 구를 사용해 집계함수로 넘겨줄 집합을 그룹으로 나눔

GROUP BY 구에 그룹화할 열을 name 으로 지정
→ 지정된 열의 값이 같은 행이 하나의 그룹으로 묶임
SELECT 구에서 name 열을 지정하였기때문에 그룹화된 name 열의 데이터가 클라이언트로 반환됨
GROUP BY 구로 그룹화된 각각의 그룹이 하나의 집합으로서 집계함수의 인수로 넘겨짐

GROUP BY name에 의해 name 열 값이 A, B, C, NULL의 네 개 그룹으로 나뉨
A 그룹에는 두 개의 행이 있는데, COUNT는 행의 개수를 반환하므로 2
A 그룹에 해당하는 quantity 값은 1, 2 이므로 SUM 값으로 3 반환
2. HAVING 구로 조건 지정
집계함수는 WHERE 구의 조건식에서는 사용할 수 없음
WHERE 구로 행을 검색하는 처리가 GROUP BY로 그룹화하는 처리보다 순서상 앞서있음
HAVING 구를 사용하면 집계함수를 사용해서 조건식을 지정할 수 있음
HAVING 구는 GROUP BY 구의 뒤에 기술
| 내부처리 순서 WHERE 구 → GROUP BY 구 → HAVING 구 → SELECT 구 → ORDER BY 구 |
3. 복수열의 그룹화
GROUP BY에 지정한 열 이외의 열은 집계함수를 사용하지 않은 채 SELECT 구에 기술해서는 안 됨
| SELECT no, name, quantity FROM sample51 GROUP BY name; name은 GROUP BY에서 지정하므로 OK, no와 quantity는 X |
집계함수를 사용하면 하나의 값으로 계산되므로 아래와 같이 작성하면 문제 X
SELECT MIN(no), name, SUM(quantity) FROM sample51 GROUP BY name;
no와 quantity로 그룹화하면 SELECT 구에 지정해도 OK
SELECT no, quantity FROM sample51 GROUP BY no, quantity;4. 결괏값 정렬
ORDER BY 구를 사용해 결과를 순서대로 정렬할 수 있음

내림차순: DESC / 오름차순(default): ASC
23강. 서브쿼리
서브쿼리 : SELECT 명령에 의한 데이터 질의로, 상부가 아닌 하부의 부수적인 질의
1. DELETE의 WHERE 구에서 서브쿼리 사용하기
ex)

sample54 테이블에서 a 열 값이 가장 작은 행을 삭제하려 함
a 열의 값이 가장 작은 행이 어느 것인지 파악할 수 없는 경우에는 SELECT 명령으로 검색할 것임
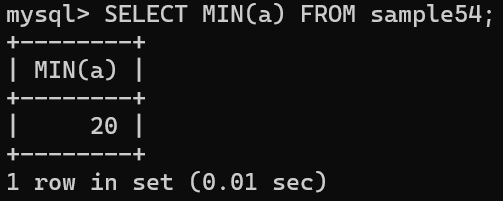
이 SELECT 명령을 DELETE 명령의 WHERE 구에서 사용하면 하나의 DELETE 명령으로 원하는 행을 삭제할 수 있음
DELETE FROM sample54 WHERE a = (SELECT MIN(a) FROM sample54);
서브쿼리를 사용하여 DELETE와 SELECT 결합
2. 스칼라 값
서브쿼리의 패턴
① 하나의 값을 반환하는 패턴
ex)

② 복수의 행이 반환되지만 열은 하나인 패턴
ex)

③ 하나의 행이 반환되지만 열이 복수인 패턴
ex)

④ 복수의 행, 복수의 열이 반환되는 패턴
ex)

패턴 ①만 하나의 값을 반환 → '단일 값', '스칼라 값' 을 반환
스칼라 값을 반환하는 SELECT 명령은 서브쿼리로서 사용하기 쉬움
WHERE 구에서 스칼라 값을 반환하는 서브쿼리는 = 연사자로 비교할 수 있음
3. SELECT 구에서 서브쿼리 사용하기
문법적으로 서브쿼리는 '하나의 항목'으로 취급
서브쿼리를 사용할 때는 스칼라 서브쿼리로 되어있는지 확인해야 함
SELECT
(SELECT COUNT(*) FROM 테이블명1) AS sq1,
(SELECT COUNT(*) FROM 테이블명2) AS sq2;
4. SET 구에서 서브쿼리 사용하기
ex) UPDATE sample54 SET a = (SELECT MAX(a) FROM sample54);
5. FROM 구에서 서브쿼리 사용하기
FROM 구에서는 스칼라 서브쿼리를 지정하지 않아도 괜찮음

SELECT 명령 안에 SELECT 명령이 들어있는 것처럼 보임 → '네스티드(nested) 구조', '중첩구조', '내포구조' 라고 부름
테이블이나 서브쿼리에 별명을 붙일 수 있음
'AS' 키워드를 사용해서 지정 (Oracle 에서는 AS 붙이면 에러 발생)
중첩 구조는 몇 단계로든 상관X
6. INSERT 명령과 서브쿼리
INSERT 명령과 서브쿼리를 조합해 사용할 수 있음
① VALUES 구의 일부로 서브쿼리를 사용하는 경우
서브쿼리는 스칼라 서브쿼리로 지정해야 하며, 자료형 일치해야 함

② VALUES 구 대신 SELECT 명령을 사용하는 경우

'INSERT SELECT' 라 불리는 명령으로 INSERT와 SELECT를 합친 것과 같은 명령이 됨
SELECT 명령이 반환하는 값이 스칼라 값일 필요X
SELECT가 반환하는 열 수와 자료형이 INSERT할 테이블과 일치하면 됨
24강. 상관 서브쿼리
EXISTS (SELECT명령)EXISTS 술어를 사용하면 서브쿼리가 반환하는 결과값이 있는지 조사할 수 있음
값이 있으면 참, 없으면 거짓을 반환
1. EXISTS
EXISTS 술어를 사용해 데이터가 존재하는지 아닌지 판별할 수 있음


sample 552에 no열의 값과 같은 행이 있으면 '있음' 이라는 값으로, 행이 없으면 '없음'이라는 값으로 갱신함
EXISTS 술어를 사용하여 서브쿼리가 행을 반환할 경우에 참을 돌려줌
2. NOT EXISTS
NOT EXISTS 를 사용하여 행이 존재하지 않는 상태가 참이 되게 함

3. 상관 서브쿼리
UPDATE sample551 SET a = '있음' WHERE
EXISTS (SELECT * FROM sample552 WEHRE no2 = no);UPDATE 명령 → 부모 / WHERE 구에 괄호로 묶은 부분, 서브쿼리 → 자식
부모 명령에서는 sample551 갱신
자식인 서브쿼리에서는 sample552 테이블의 no2 열 값이 부모의 no 열 값과 일치하는 행을 검색
부모 명령과 자식인 서브쿼리가 특정 관계를 맺는 것 → '상관 서브쿼리'
상관 서브쿼리가 아닌 서브쿼리는 단독 쿼리로 실행할 수 O
상관 서브쿼리에서는 부모 명령과 연관되어 처리되기 때문에 서브쿼리 부분만 따로 떼어내어 실행 시킬 수 X
- 테이블명 붙이기
위의 예제에서 sample551의 열과 sample552의 열이 no, no2로 다르기때문에 제대로 동작했으나
만약 같은 경우 WHERE no=no 가 되면 제대로 동작하지 않음
이런 경우, 정상적으로 처리하기 위해 열이 어느 테이블의 것인지 명시적으로 나타내야 함
열명 앞에 '테이블명.'을 붙이면 됨
ex)
UPDATE sample551 SET a = '있음' WHERE
EXISTS (SELECT * FROM sample552 WHERE sample552.no2 = sample551.no);
4. IN
스칼라 값끼리 비교할 때는 = 연산자 사용하지만, 집합을 비교할 때는 사용 x
IN을 사용하면 집합 안의 값이 존재하는지 조사할 수 있음
서브쿼리를 사용할 때 IN을 통해 비교
열명 IN(집합)IN에서는 오른쪽에 집합을 지정
왼쪽에 지정된 값과 같은 값이 집합 안에 존재하면 참 반환
집합은 상수 리스트를 괄호로 묶어 기술
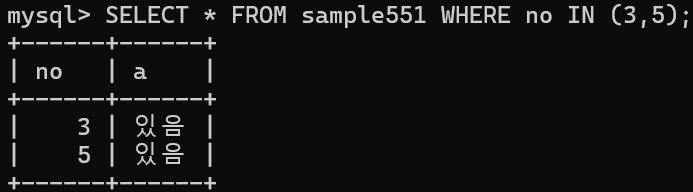
집합 부분은 서브쿼리로도 지정할 수 있음

서브쿼리는 스칼라 서브쿼리일 필요 X
NOT IN으로 지정하면 집합에 값이 포함되어 있지 않을 경우 참
- IN과 NULL
IN에서는 집합 안에 NULL 값이 있어도 무시하지X
다만, IN을 사용해도 NULL 값은 비교할 수 없음
IS NULL을 사용해야 함
NOT IN의 경우, NULL 값이 있으면 참을 반환하지X, '불명(UNKNOWN)'이 됨
'ECC - 백엔드 > SQL 첫걸음' 카테고리의 다른 글
| 7장 복수의 테이블 다루기 (0) | 2024.11.02 |
|---|---|
| 6장 데이터베이스 객체 작성과 삭제 (0) | 2024.10.12 |
| 4장 데이터의 추가, 삭제, 갱신 (0) | 2024.10.05 |
| 3장 정렬과 연산 (0) | 2024.10.05 |
| 2장 테이블에서 데이터 검색 (0) | 2024.09.27 |